Count data is commonly modelled using a generalised linear model with a Poisson likelihood, and this approach extends trivially to cases with multiple count data random variables, \(Z_i\in\mathbb{Z}^{0+}, i=1\ldots N\) which are independent of one another, \(Z_i\perp Z_j, \forall i,j\) because the likelihoods factor out nicely. But what about the case where there is some correlation?
In this short post I’ll describe the case in which we have two correlated count variables and we believe that a linear function of some known covariates can explain variation in the data.
Univariate Poisson regression and the MLE fit
The poisson distribution is specified by a parameter, \(\lambda_i\in\mathbb{R}\), which turns out to be both its mean and variance. It’s PMF for an observation, \(z_i\), is given by
$$ \text{Po}(z_i | \lambda_i) = \frac{\lambda_i^{z_i}e^{-\lambda_i}}{z_i!}. $$
Assuming the data is IID the log-likelihood is given by:
$$ \mathcal{L}(\lambda_i | z_i) = \sum_i^n z_i\log(\lambda_i) - \lambda_i - \log(z_i!). $$
The last piece we need, a ’link function’: There are a couple of options we can use to relate the Poisson parameter to our model parameters, \(\beta_j\), and the observed covariates, \(z_j\), but the common choice is the log-link:
$$ \log\lambda_i = \vec{\beta}\cdot \vec{x_i} $$
Typically we would take derivatives of the log-likelihood with respect to the \(w_j\) using the chain rule and use the iteratively reweighted least squares algorithm (see page 294 of [1] for details on that approach) but here we can be lazy and let scipy’s brentq minimisation do the hard work for us (this will require more function evaluations than if we provided the derivative of the negative log-likelihood and prefered L-BFGS over brentq, but everything here runs in O(seconds) on my laptop anyway)
We’re nearly ready to start fitting some models, but first some housekeeping to make our life easier later:
| |
We can generate some fake data from a true model lambdas by generating some random covariates and using some true model \(\beta\)’s, and then sampling from the resulting Poisson distributions:
| |
and, as above, in order to fit the model we need an expression for the negative (so make the problem is a minimisation) log-likelihood and for neatness, and further use, we’ll want a little wrapper around scipy’s minimise function:
| |
and with these we can generate, and fit, some Poisson data from the following model:
\begin{align} p(z_i | \vec{x}_i, \vec{\beta}) &\sim \text{Po}(\lambda_i) \nonumber \\ \log(\lambda_i) &= 1 + 2x_1 - x_2 \nonumber \end{align}
| |
Of course the usual caveat applies – if you’re trying to build a univariate Poisson regression in python, don’t use my code - do it using statsmodels:
| |
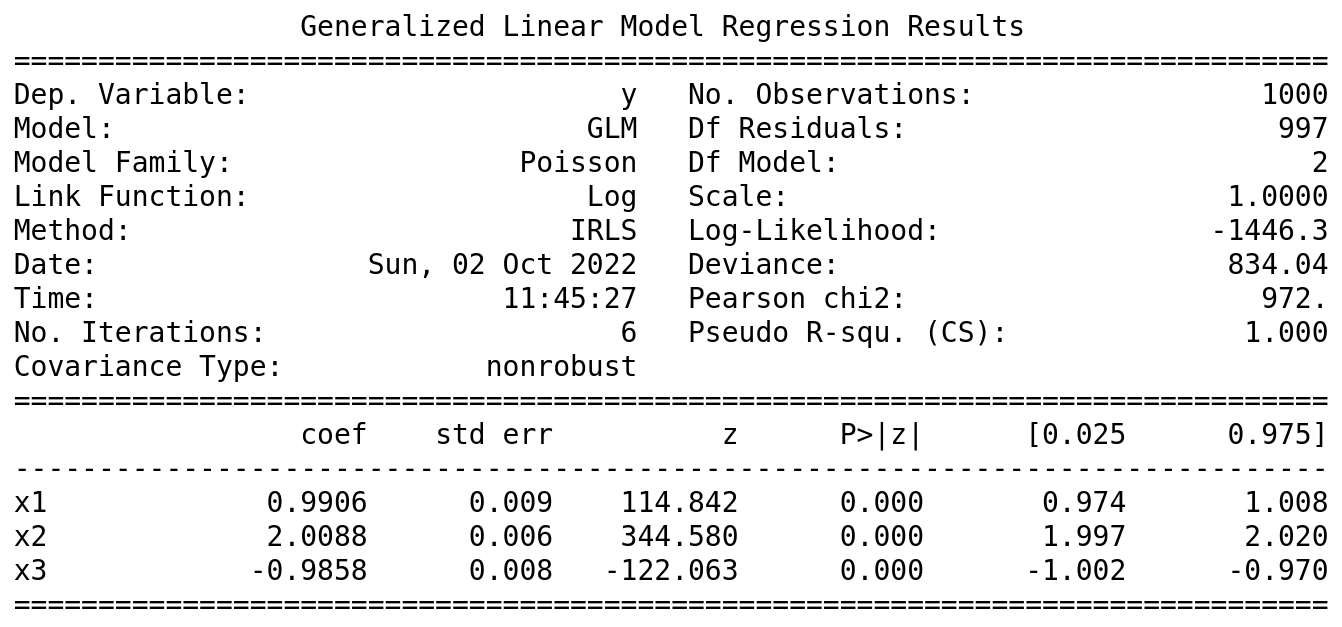
We can see that our fit is in good agreement with statsmodels, but we also get lots of other interesting information (coefficient uncertainty, NLL, deviance, etc.).
Correlations between two Poisson random variables
As mentioned in the introduction, if we have two Poisson random variables, \(Z_1\) and \(Z_2\), with no correlation (known as the ‘Double Poisson’ model) then the above approach still holds since the likelihood factorises:
\begin{align} \text{Po}(z_{1i}, z_{2i} | \lambda_{1i}, \lambda_{1i}) = \frac{\lambda_{1i}^{z_{1i}}e^{-\lambda_{1i}}}{z_{1i}!}\cdot\frac{\lambda_{2i}^{z_{2i}}e^{-\lambda_{2i}}}{z_{2i}!}. \nonumber \end{align}
\begin{align} \Rightarrow \mathcal{L}(\lambda_{1i}, \lambda_{2i} | z_{1i}, z_{2i}) &= \sum_i^n \big(z_{1i}\log(\lambda_{1i}) - \lambda_{1i} - \log(z_{1i}!)\big) + \nonumber \\ &\quad \sum_i^n \big(z_{2i}\log(\lambda_{2i}) - \lambda_{2i} - \log(z_{2i}!)\big) \nonumber \end{align}
and to maximise this we can just maximise the two sums separately. When doing so all of derivate crossterms, \(\partial _ {\vec{\beta} _ n} \vec{\lambda} _ m\), are zero for \(n \neq m\) because of our ’no correlation’ stipulation.
But what if we suspect that our two random variables are correlated?
The Bivariate Poisson model deals with exactly this case – let \(Y_0, Y_1, Y_2\) be independent univariate Poisson distributed with parameters \(\lambda_0, \lambda_1, \lambda_2\) respectively. Then
\begin{align} Z_0 &= Y_0 + Y_2 \nonumber \\ Z_1 &= Y_1 + Y_2 \nonumber \end{align}
are bivariate poisson distributed. Clearly \(Z_0\) and \(Z_1\) are maginally Poisson and therefore we have:
\begin{align} \mathbb{E}[Z_0] &= \lambda_0 + \lambda_2 \nonumber \\ \mathbb{E}[Z_1] &= \lambda_1 + \lambda_2 \nonumber \end{align}
since sums of two independent Poisson distribution results in another Poisson parametrised by the sum of the two input distribution parameters. But more interestingly we also have
\begin{align} \text{Cov}(Z_0, Z_1) &= \text{Cov}(Y_0 + Y_2, Y_1 + Y_2) \nonumber \\ &= \text{Cov}(Y_0, Y_1) + \text{Cov}(Y_0, Y_2) + \text{Cov}(Y_2, Y_1) + \text{Cov}(Y_2, Y_2) \nonumber \\ &= \text{Cov}(Y_2, Y_2) \nonumber \\ &= \text{Var}(Y_2) \nonumber \\ &= \lambda_2 \nonumber \end{align}
where \(\text{Cov}(Y_i, Y_j) = 0\) for \(i\neq j\) by constrution of the \(Y_j\)’s.
The PMF of the Bivariate Poisson model is given by:
$$ f_\text{BP}(Z_0, Z_1 | \lambda_0, \lambda_1, \lambda_2) = e^{-\lambda_0-\lambda_1-\lambda_2}\frac{\lambda_0^{z_0}}{z_0!}\frac{\lambda_1^{z_1}}{z_1!}\sum_{k=0}^{\min({z_0, z_1})} \binom{z_0}{k}\binom{z_1}{k}k!\left(\frac{\lambda_2}{\lambda_1\lambda_1}\right)^k $$
We can see that when \(\lambda_2\rightarrow0\) this reduces to the Double Poisson model since only the \(k=0\) term in the sum contributes and it contributes \(1\), leaving only the coefficient in front remaining.
The problem we now have to solve then is:
\begin{align} Z_{0i}, Z_{1i} &\sim \text{BP}(Z_{0i}, Z_{1i} | \lambda_{0i}, \lambda_{1i}, \lambda_{2i}) \nonumber \\ \log\lambda_{ki} &= \vec{\beta_k} \cdot \vec{x_{i}} \nonumber \end{align}
where \(i\) indexes over the paired datapoints and \(k=1\ldots3\), and associated covariates. It is possible that the \(\lambda_k\) depend on different (or even distinct) subsets of the covariates, but we can always treat this case using a single \(\vec{x_{i}}\) created by concatenating the different features and enforcing that the pertinent components of \(\beta\) are zero.
Fitting the Bivariate Poisson with the EM algorithm
We saw above that we can directly maximise the likelihood of a univariate Poisson distribution, but with the Bivariate Poisson case it is more awkward. The unobserved nature of \(Y_2\) means that there is not a neat closed form expression for MLE.
Instead we can follow the approach taken in the Karlis and Ntzoufras paper [2] and take an Expectation-Maximisation approach [3] [4]. I also recommend Ntzoufras’s book which describes lots of interesting models [5].
Computing The Likelihood
We can write down a seemingly useless form for the bivariate model, one expressed in terms of all three of the unobserved Poisson components:
$$ f(Y_0, Y_1, Y_2 | \Theta) = \prod_{i=1}^n \prod_{k=1}^3 \frac{e^{-\lambda_i} \lambda_i^{y_k}}{y_k!} $$
We can perform a change of variables so that our model is in terms of the two observed random variables \((Z_0, Z_1)\) and a single latent variable \(Y_2\), the determinant of the Jacobian of the transformation is 1 so we have
\begin{align} L(\lambda_0, \lambda_1, \lambda_2 | Z_0, Z_1, Y_2) &= \prod_{i=1}^n \frac{e^{-\lambda_0} \lambda_0^{z_{0i} - y_{2i}}}{(z_{0i} - y_{2i})!} \frac{e^{-\lambda_1} \lambda_1^{z_{1i} - y_{2i}}}{(z_{1i} - y_{2i})!} \frac{e^{-\lambda_2} \lambda_2^{y_{2i}}}{y_{2i}!} \nonumber \end{align}
and therefore the log-likelihood is
\begin{align} \mathcal{L}(\lambda_0, \lambda_1, \lambda_2 | Z_0, Z_1, Y_2) &= -n\lambda_0 + \sum_{i=1}^n(z_{0i} - y_{2i})\log\lambda_0 - \log\prod_{i=1}^n(z_{0i} - y_{2i})! \nonumber \\ &\quad -n\lambda_1 + \sum_{i=1}^n(z_{1i} - y_{2i})\log\lambda_1 - \log\prod_{i=1}^n(z_{1i} - y_{2i})! \nonumber \\ &\quad -n\lambda_2 + \sum_{i=1}^n y_{2i}\log\lambda_2 - \log\prod_{i=1}^ny_{2i}! \nonumber \end{align}
This is almost the same as the ‘Double Poisson’ model and we know we can maximise it with respect to the \(\lambda\)’s, except that we don’t know the value of the \(y_{2i}\). This is where the Expectation-Maximisation algorithm comes in.
Computing The Density of the Latent Variable
To get the \(\mathcal{Q}\) function we need to compute the expectation of the log-likelihood with respect to the density \(f(Y_2|Z_0, Z_1, \lambda_k^{(t)})\), where \(\lambda_k^{(t)}\) are our current guess for the lambdas. Using Baye’s theorem we can write this as:
$$ f(Y_2|Z_0, Z_1, \lambda_k^{(t)}) = \frac{f(Z_0, Z_1 | Y_2, \lambda_k^{(t)})f(Y_2 | \lambda_k^{(t)})}{f(Z_0, Z_1 | \lambda_k^{(t)})} $$
The denominator is just the Bivariate Poisson density and \(f(Y_2 | \lambda_k^{(t)})\) is just the Poisson density. The last term, \(f(Z_0, Z_1 | Y_2, \lambda_k^{(t)})\), is a little harder to reason about – but if we look to the definitions \(Z_0, Z_1\) and imagine that \(Y_2\) is just a constant we see the following is true
$$ f(Z_0, Z_1 | Y_2, \lambda_k^{(t)}) = f(Y_0 = Z_0 - Y_2 | \lambda_k^{(t)})f(Y_1 = Z_1 - Y_2 | \lambda_k^{(t)}) $$
and both of the distributions on the right-hand side are just more Poisson distributions. Thus:
$$ f(Y_2|Z_0, Z_1, \lambda_k^{(t)}) = \frac{\text{Po}(Y_0 = Z_0 - Y_2 | \lambda_k^{(t)})\text{Po}(Y_1 = Z_1 - Y_2 | \lambda_k^{(t)})\text{Po}(Y_2 | \lambda_k^{(t)})}{f_\text{BP}(Z_0, Z_1 | \lambda_k^{(t)})} $$
Computing The Expectation of the Latent Variable
With this density computed we can compute the expectation of the unobserved \(Y_2\) conditioned on the observed data:
$$ \mathbb{E} _ {Y_2|Z_0, Z_1, \lambda _ k^{(t)}}[Y _ 2] = \sum_{j=0}^\infty j\frac{\text{Po}(z_0 - j | \lambda_0)\text{Po}(z_1 - j | \lambda_1)\text{Po}(j | \lambda_2)}{f_\text{BP}(Z_0, Z_1 | \lambda_k^{(t)})} $$
The denominator is independent of our index, \(j\), and we can change the bounds of the summation in two ways:
- Firstly we can use that fact that the \(j=0\) term in the sum is clearly zero to shift the start of the summation,
- Secondly we see that for any \(j>z_0\) or \(j>z_1\) the Poisson density is zero (the domain of the Poisson is non-negative integers). Therefore the upper bound of the sum is \(\max(z_0, z_1)\).
Therefore
$$ \mathbb{E}[Z_0]= \frac{1}{f_\text{BP}(Z_0, Z_1 | \lambda_k^{(t)})}\sum_{j=1}^{\max(z_0, z_1)} j \ \text{Po}(z_0 - j | \lambda_0)\text{Po}(z_1 - j | \lambda_1)\text{Po}(j | \lambda_2) $$
Substituting in the density of the Poisson (and suppressing, for now, the EM iteration index \((t)\))
$$ \mathbb{E}[Z_0]= \frac{1}{f_\text{BP}(Z_0, Z_1 | \lambda_k)}\sum_{j=1}^{\max(z_0, z_1)} j \frac{\lambda_0^{z_0 - j} e^{\lambda_0}}{(z_0 - j)!} \frac{\lambda_1^{z_1 - j} e^{\lambda_1}}{(z_1 - j)!} \frac{\lambda_2^{j} e^{\lambda_2}}{j!} $$
We can pull out some factors of the lambdas:
$$ \mathbb{E}[Z_0] = \frac{\lambda_2 e^{-\lambda_0-\lambda_1-\lambda_2}\lambda_0^{z_0-1}\lambda_1^{z_1-1}}{f_\text{BP}(Z_0, Z_1 | \lambda_k)} \sum_{j=1}^{\max(z_0, z_1)} j \frac{1}{(z_0 - j)!(z_1 - j)!j!}\left(\frac{\lambda_2}{\lambda_1\lambda_1}\right)^{j - 1} $$
Now some more index trickery, we let \(p = j - 1\) in the sum:
\begin{align} &= \frac{\lambda_2 e^{-\lambda_0-\lambda_1-\lambda_2}\lambda_0^{z_0-1}\lambda_1^{z_1-1}}{f_\text{BP}(Z_0, Z_1 | \lambda_k)} \sum_{p = 0}^{\max(z_0 - 1, z_1 - 1)} (p + 1) \frac{1}{(z_0 - p - 1)!(z_1 - p - 1)!(p + 1)!}\left(\frac{\lambda_2}{\lambda_0\lambda_1}\right)^{p} \nonumber \\ &= \frac{\lambda_2 e^{-\lambda_0-\lambda_1-\lambda_2}\lambda_0^{z_0-1}\lambda_1^{z_1-1}}{f_\text{BP}(Z_0, Z_1 | \lambda_k)(z_0 - 1)!(z_1 - 1)!} \sum_{p = 0}^{\max(z_0 - 1, z_1 - 1)} \frac{(z_0 - 1)!(z_1 - 1)!}{(z_0 - p - 1)!(z_1 - p - 1)!p!}\left(\frac{\lambda_2}{\lambda_0\lambda_1}\right)^{p} \nonumber \end{align}
we recognise the combination of factorials inside the sum as binomial coefficients
\begin{align} &= \frac{\lambda_2 e^{-\lambda_0-\lambda_1-\lambda_2}\lambda_0^{z_0-1}\lambda_1^{z_1-1}}{f_\text{BP}(Z_0, Z_1 | \lambda_k)(z_0 - 1)!(z_1 - 1)!}\sum_{p = 0}^{\max(z_0 - 1, z_1 - 1)} {z_0 - 1\choose p} {z_1 - 1\choose p} p! \left(\frac{\lambda_2}{\lambda_0\lambda_1}\right)^{p} \nonumber \end{align}
and finally we have:
\begin{align} y_2^{(t)} \equiv \mathbb{E} _ {Y_2|Z_0, Z_1, \lambda _ k^{(t)}}[Y _ 2] &= \lambda_2\frac{f_\text{BP}(Z_0 - 1, Z_1 - 1 | \lambda_k^{(t)})}{f_\text{BP}(Z_0, Z_1 | \lambda_k^{(t)})} \nonumber \end{align}
The EM algorithm
The auxilliary function, \(\mathcal{Q}\), is then just the log-likelihood where we use the expected value for the latent variable we just computed
\begin{align} \mathcal{Q}(\lambda | \lambda_{k}^{(t)}) &= -n\lambda_0 + \sum_{i=1}^n(z_{0i} - y_{2i}^{(t)})\log\lambda_0 \nonumber \\ &\quad -n\lambda_1 + \sum_{i=1}^n(z_{1i} - y_{2i}^{(t)})\log\lambda_1 \nonumber \\ &\quad -n\lambda_2 + \sum_{i=1}^n y_{2i}^{(t)}\log\lambda_2 \nonumber \end{align}
where the terms which don’t depend on \(\lambda_k\) have been dropped. Remembering for a moment that the lambdas are themselves functions of the regression weights:
$$ \log\lambda_{ki} = \vec{\beta_k} \cdot \vec{x_{i}} $$
we can see that to maximise the \(\mathcal{Q}\) function we have to perform three separate Poisson regressions:
to compute the weights \(\beta\). In summary then the EM iterations look like this:
- E-step: Using our current best guess for the model weights, \(\beta^{(t - 1)}\), we compute \(y_{2i}^{(t)}\) for each datapoint,
- M-step: We perform the follow three Poisson regressions \begin{align} z_{0i} - y_{2i}^{(t)} &\sim \text{Po}(\lambda_{0i}^{(t-1)}), \ \log\lambda_{0i}^{(t-1)} = \vec{\beta_0}^{(t-1)}\cdot\vec{x_i} \nonumber \\ z_{1i} - y_{2i}^{(t)} &\sim \text{Po}(\lambda_{1i}^{(t-1)}), \ \log\lambda_{1i}^{(t-1)} = \vec{\beta_1}^{(t-1)}\cdot\vec{x_i} \nonumber \\ y_{2i}^{(t)} &\sim \text{Po}(\lambda_{2i}^{(t-1)}), \ \log\lambda_{2i}^{(t-1)} = \vec{\beta_2}^{(t-1)}\cdot\vec{x_i} \nonumber \end{align}
to find our next estimates for the model weights \(\vec{\beta_2}^{(t)}\).
Implementation in python
And now lets implement all of this in python. We start by generating the latent \(Y_j\) data from independent Poissons and the combining them to form the \(Z_i\):
| |
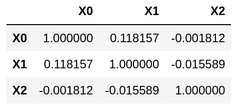
We can check the correlation matrix of the latent data, and the observed data to see that this has worked as expected:
| |
| |
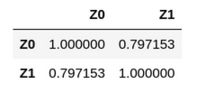
The \(Z_i\)’ have a strong degree of correlation, so far so good. We need the Bivariate Poisson density, \(f_\text{BP}(Z_0, Z_1 | \lambda_0, \lambda_1, \lambda_2)\):
| |
For the E-step of the EM algorithm we must compute the expectation \(y_2^{(t)} = \mathbb{E} _ {Y_2|Z_0, Z_1, \lambda _ k^{(t)}}[Y _ 2]\) for each datapoint, \(i\):
| |
For the M-step we can re-use the 1D Poisson regression code from earlier in this post to compute the betas, and from the betas we get our new estimate for the lambdas:
| |
That is everything we really need to fit this model, but to make the output more interesting we should include a little extra code to track the negative log-likelihood of the model, and the mean squared error to see that the EM algorithm is converging:
| |
And finally we fit the model:
| |
we can compare the model fitted \(\beta\) values to the true \(\beta\)’s and see that they are in good agreement:
| |
We can also perform a Double Poisson fit and compare the MSE of the two models.
| |
which is significantly worse than the 9.054 managed by the Bivariate Poisson regression.
References
[1]: Machine Learning A Probabilistic Perspective (K. P. Murphy)
[2]: Bivariate Poisson and Diagonal Inflated Bivariate Poisson Regression Models in R