Intro to robustness: optimality and feasibility
In the next few posts I’m going to work through a paper by Bertsimas and Sim [1] which looks at an interesting approach to making robust decisions using mixed integer linear programmes when dealing with uncertainty in training data. In particular I’ll solve the ‘Knapsack Problem’ in three different ways and then discuss the trade-off: how can we best balance the optimality of our solutions with their feasibility?
In this post I’ll start by briefly introducing the Knapsack Problem and then looking at Soyster’s method for dealing with uncertainty. In the subsequent one or two posts I’ll derive the Bertsimas and Sim model and implement it in gurobi.
The Knapsack Problem
The Knapsack problem is the following simple task: Choose to fill our bags (‘knapsacks’) indexed by \(j\) from a set of available objects indexed by \(i\). Each object has with it an associated value, \(c_i\), and a ’nominal’ weight, \(w_i\). We want to maximise the total value of objects in our bags while not exceeding the weight limits of each, \(l_j\):
$$ \begin{align*} &\max \sum_{i,j} x_{ij} c_i\newline&\text{subject to:}\quad \sum_i x_{ij}w_i\leq l_j \end{align*} $$
where \(x_{ij}\in\{0, 1\}\) are our binary decision variables which indicate if we have chosen to take item \(i\) in knapsack \(j\).
If instead we solved the relaxation \(0\leq x_{ij}\leq 1\) that is known as the continuous knapsack. I’ll focus on solutions to the binary (or zero-one) knapsack problem although the code presented supports both.
Expressing this with the gurobi optimiser is straightforward. Starting with a definition of our problem:
| |
A method to generate example problems to solve (’nominal’ here indicates we are dealing with a single value for the weight of each item, with no uncertainty):
| |
and a gurobipy model to find:
- the optimal knapsack allocation for a given problem,
- the objective value (in our case, the total value of the items)
- details of which items were allocated to each knapsack (which will come in handy later for checking the feasibility of our solutions in various settings)
| |
And giving it a quick test run…
| |
Good. This should solve extremely fast and the model will, I believe, be small enough to run on the free gurobipy license.
Now moving on to the more interesting stuff.
Uncertainty in our constraint matrix
To describe the situation where we have uncertainty in our weights I will follow the language in [1].
We assume that each entry of our weight constraint matrix, \( \tilde w_{ij}\), is a random variable which can assume values around the ’nominal’ value, \(w_{ij}\), as follows:
$$ \tilde w_{ij} \in [w_{ij} − \hat w_{ij} , w_{ij} + \hat w_{ij}]. $$
For what follows it will also be useful to define:
$$ \eta_{ij} = \frac{(\tilde w_{ij} − w_{ij})}{\hat w_{ij}}, $$
which, by construction, is a symmetric distribution satisfying \(\eta_{ij} = [−1, 1]\).
Soyster’s approach & Murphy’s Law
In Soyster’s paper of 1973 [3] he phrased this problem by considering each weight variable to have a set of possible values and then expanding out the total weight constraint into every combinatorial realisation giving every variable, \(w_i\), its minimum and maximum possible value.
This is the Operational Research version of Murphy’s Law - we are looking at all possible cases and then will focus solely on the ‘worst’ possible scenario. In our case the ‘worst’ case is the one where all of the objects we decide to pick will be at their maximum allowed weight value. It’s going to be extremely conservative which will lead to two important properties of the solutions it finds:
- The good news: The solution we choose will always remain feasible no matter what weights are drawn for the random variables - whatever plan we come up is provably going to work out!
- The bad news: It’s highly likely that when we know the realised weights of the objects we’ll find out that our plan was way too conservative and this has led us to a solution which is less valuable than it might have been.
The proof of the feasibility again comes from [1]. Start by expanding out the constraint term in terms of \(w_{ij}\) and \(\hat{w}_{ij}\) decomposition:
$$ \sum_j x_j\tilde w_{ij} = \sum_j x_j(w_{ij} + \eta\,\hat{w}_{ij}) \leq l_i $$
$$ \sum_j x_jw_{ij} + \sum_jx_j\eta\,\hat{w}_{ij} \leq l_i $$
Now comes the Soyster ‘worst case’; in place of the \(x_j\,\eta\) term we introduce a new variable \(y_j \geq 0\) which we bound to be greater in magnitude than \(x_j\):
$$ -y_j \leq x_j \leq y_j $$
Leaving our constraint term as
$$ \sum_j x_jw_{ij} + \sum_jy_j\hat{w}_{ij} \leq l_i. $$
Although it looks like we’re allowing the magnitude of the error to be larger than that allowed by the \(|\eta|\leq 1\) constraint we will find that at optimality the constraint linking \(x_j\) and \(y_j\) will be ’tight’ i.e. we will have \(y_j^*=|x_j^*|\) (when an asterisk denotes the value for the corresponding variable once the MIP has been solved to optimality).
It’s easy to show that the optimal values to this Soyster problem will remain feasible for any realisation of the weights of the objects:
$$ \sum_j \tilde w_{ij}x_j^* = \sum_j w_{ij}x_j^* + \sum_j \eta_{ij}\hat{w}_{ij}x_j^* $$
$$ \leq \sum_j w_{ij}x_j^* + \sum_j |x_j^*|\hat{w}_{ij} $$
$$ = \sum_j w_{ij}x_j^* + \sum_j y_j\hat{w}_{ij} \leq l_i $$
Solving the Soyster problem
To demonstrate these good news/bad news properties we can take a nominal problem with some weight uncertainty, and generate the Soyster version of our problem, which optimise_knapsack_model can solve:
| |
We can also use the definitions of the random weight variables to generate realisations which deviate from the nominal problem. In this way we can compare objective values of the Soyster formulation with ‘reality’ and also check to see how often our ’nominal’ and Soyster solutions remain feasible once we know the actual weights of the knapsack items:
| |
| |
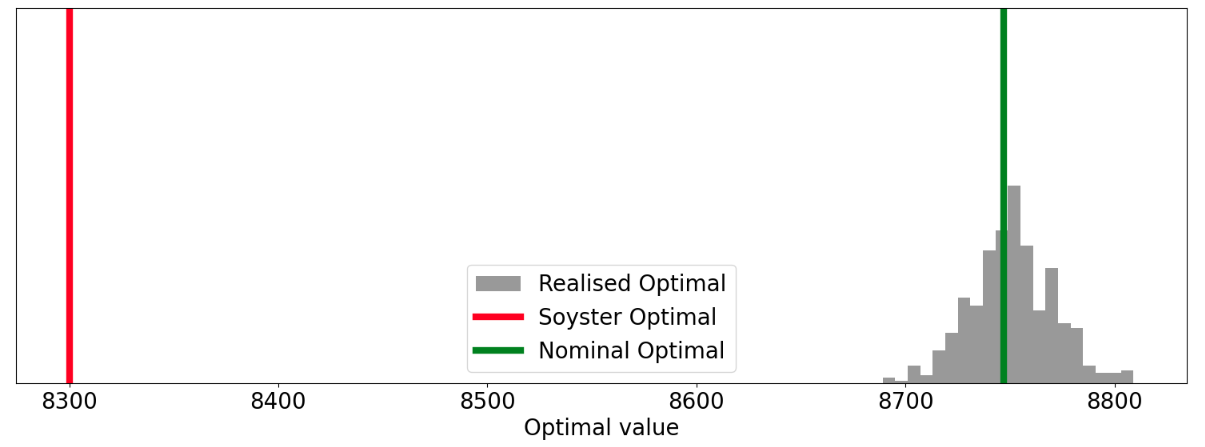
We can see that every realised set of weights is feasible under the Soyster solution but that if we just optimised assuming the mean weights our plan only remained valid 34.2% of the time! We can also see from the distribution of realised optimal values that the Soyster solution is leaving a not insignificant amount of value on the table…Is there a way we can trade off these two goals in a more graceful way?
Yes (obviously)! In the next post, or two, I’ll continue on and derive the more flexible Bertsimas and Sim alternative.
References
[1]: The Price of Robustness - Bertsimas and Sim
[2]: Theory and applications of Robust Optimization - Bertsimas et. al.
[4]: Data-Driven Robust Optimization Using Scenario-Induced Uncertainty Sets - Cheramin et. al.